Did some testing of generating RPG maps with an AI. It’s surprisingly difficult. Thought I would share the outcome.
The prompt:
Generate a map for a tactical RPG with top-down ortographic projection – planimetric view, with high detail, of this place:
An underground soviet-era bunker, industrial horror style.
The planimetry includes:
1. A massive central workshop with piling rubble, heavy machinery, and a production of bolts and other materials.
2. A NKVD high-security conference room, with a single desk and monitor, near a small jail.
3. A small dormitory with bunk beds connected to a restroom which has an exposed eletrical panel.
My results, roughly listed from cheap to expensive model.
Qwen-image. Not orthogonal, and very very few of the requested details.

Qwen/Qwen-Image-2.0. Improved and offered good detail, but still doors are missing and it’s not orthogonal. Also, we have some really huge bolts here.

Juggernaut-Lightning-Flux. Not much detail, some of which look weird, some doors missing, and gravity looks off.

stabilityai/stable-diffusion-xl-base-1.0. Overall seems just confusing.

HiDream-ai/HiDream-I1-Fast. Interesting style, but not orthogonal.

stabilityai/stable-diffusion-3-medium. Every detail looks just confused; I can’t tell what is what.

RunDiffusion/Juggernaut-pro-flux. Gravity is off and there isn’t much detail.

HiDream-ai/HiDream-I1-Dev. Usable, but overall didn’t follow the prompt very closely.

HiDream-ai/HiDream-I1-Full. Usable but again it didn’t follow the prompt very closely.

Lykon/DreamShaper. Doesn’t look like it followed the prompt very much.

black-forest-labs/FLUX.2-dev. Looks actually pretty good and usable. The prompt was mostly followed. The amount of detail is ok. It could improve, but you can tell what most of the things are.

ByteDance-Seed/Seedream-3.0. Not bad, but not orthogonal and lacking doors.

ByteDance-Seed/Seedream-4.0. Still not orthogonal and lacking doors.

google/flash-image-2.5. Usable, although with some confused details.

google/imagen-4.0-fast. Somewhat usable but doors are missing and gravity is off.

black-forest-labs/FLUX.2-flex. Pretty good. Some doors missing. Not so orthogonal but usable.

black-forest-labs/FLUX.2-pro. Actually slightly worse than the previous. Rooms are a bit confused. Text is accurate, but it wasn’t asked for. Weird doors. Not so orthogonal. Still usable.

openai/gpt-image-1.5. High amount of detail. More rooms than asked. Some doors missing and some weird details, but overall good.

Wan-AI/Wan2.6-image. Somewhat usable but gravity is off and some details are confused.

Not tested here: more recent/advanced models like Nano Banana, yes they are better, but they are also more expensive.
As such my winner for this experiment is FLUX.2-dev: it followed the requirement accurately enough, and it’s still a very cheap model.












 and
and  are the two sets, and
are the two sets, and 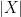 and
and 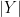 are their size.
are their size. 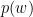 is the probability of item
is the probability of item  (simply put, the frequency of word
(simply put, the frequency of word 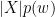 is the probability of
is the probability of 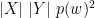 is the probability an item
is the probability an item
You must be logged in to post a comment.