Today we talk about how you shouldn’t measure sentence similarity.
“Bag of words” is a simplified model of handling sentences in natural language processing, which disregards grammar, punctuation, and word order and manages sentences as sets of words.
“Set similarity” is a measure of the distance between two sets (two collections of arbitrary items). There are many approaches in literature; I recently came across the Jaccard Index, while other alternatives are Sorensen Similarity Index and Hamming distance.
Jaccard Index (or Jaccard Distance) seems to be commonly used in text summarization algorithms, which use it to measure the similarity between two sentences (using a sentence as a set of words).
However Jaccard Index has some sub-optimal quirks. Its score is based on the number of items shared between the sets; when applied to sentence comparison, there are words that are very common (e.g. stopwords), especially in modern social network environments (e.g. Instagram hashtags), often used across different contexts (e.g. #picoftheday); I quickly realized not all words should be treated equally when measuring sentence similarity, and it is not trivial to evaluate if words are important or not.
Its score is also weighted on the set cardinality (the total number of words in the sentence); however this favours short sentences, for example it is way easier to have two sentences share all of their words when there is only one word in them. Big sets that have a large percentage of their items in common should get higher matching scores than smaller sets that have a similar percentage of matching items, since this has a smaller probability to happen for large sets.
This is where I tried to formulate a different, more context-aware, non-normalized, language-agnostic measure of similarity between sentences. I called this algorithm Spaghetti Distance Index. Its idea is, given two sentences, to measure the log-likelihood of ending up with a certain number of shared words. In formulas:



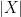
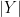
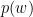

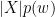
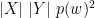
This algorithm has some advantages over Jaccard Index:
- the similarity score is unbounded, so longer sentences can have higher scores;
- it favours high percentages of matching words, non-shared words have a negative impact on score;
- uncommon words contribute more to the score;
- it maintains language agnosticity, and can be used to compare any set of items.
This algorithm assumes each word as chosen indipendently from the others; this is literally what a “bag of word” would get you if words are chosen blindly and randomly. On the other hand, this assumption is certainly not true: words in a sentence have a correlation between them. This is especially true for sentences belonging to a certain topic, i.e. if sentences are about pasta recipes, and one word is spaghetti, then there would be a somewhat high probability of another word being tomato.
Factorizing in the correlation between words would bring us to the Mutual Information algorithm, which relies exactly on the probability of a certain word given all the other words.
But if the problem is comparing sentence similarity, then possibly there are other domain-specific similarity measures such as tf-idf (which accounts for both term frequency in sentences, and for general term frequency among all words), BM25, or sentence clustering algorithms such as Latent Dirichlet allocation.
You can see the source code for Spaghetti Distance Index on GitHub.