It all started with a problem which seem to be simple and already seen around in the real world:
I just need a simple script to restart a process if it crashes.
Simple enough right? So simple that I wanted to use a short bash script to do it. Turns out it’s not really that simple, especially if your thought process continues with
And I will use signals to control it.
Okay, now it’s really a bad idea which can fail for a lot of reasons:
1. Checking if a process has crashed is not idiot-proof
The idiot being the one that writes a C program that exits main() with “return(-1);” or any other negative value. The exit status is a signed byte, thus a negative value will wrap around to a > 127 value and be indistinguishable from a process crash.
A program exiting with “return(-119);” has the same exit status as one killed with kill -9 (SIGKILL). The fun!
2. You can’t always control signals in bash
According to POSIX specs, bash can’t change the signal handler for signals which were ignored in the parent process. So this script would be unusable if you happen to launch it from a process which has the relevant signals ignored. That’s where I got the idea to use a one-line python wrapper around my bash script to enable all signals before giving control to bash.
3. Using a signal wrapper spawns a second process
It turned out quickly that it wasn’t a great idea. Using a python wrapper around a bash script will obviously generate a second process, one for bash and one for python.
So in just one move I spawned three more problems:
– the python wrapper has the process name you would expect (the wrapper name) and has every signal enabled, i.e. any signal would kill it
– the bash script has a different process name which makes it counter-intuitive which one is the process to send signals to
– the bash script starts after the python wrapper so if two wrappers start simultaneously, we have a funny race condition to deal with.
So, I just decided to drop bash and rewrite everything in python instead.
4. There is no standard signal to ask a process to restart
Usually it’s SIGHUP, but it’s not universally true. If your controlled process can be restarted with a signal, that signal should be SIGHUP, but no guarantees.
5. Signals are not setup immediately at startup
When your control script starts, all signals have their default handler. So for example if you launch your control script and then immediately decide to restart the controlled process (with a SIGHUP signal), it may happen that the controller gets killed instead, and the child process is left with no control.
6. SIGKILL can’t be handled
If your control script is killed with SIGKILL, the child process is left running with no control.
7. The child process exiting will have interesting race conditions
Say for example that the restart behaviour will be to send SIGHUP to the child process, wait for its exit, and launch the child process again.
If your control script is asked to restart the child process several times in a row, it might be sending several signals to a PID, which after the first SIGHUP might not correspond to any running process (not so bad) or correspond to a different process recently spawned (definitely not good).
In certain *NIX flavours you can setup a signal handler that will fire when the child process exits, but based on my research this is not true for every OS out there.
8. There is no alternative to signals
I might have finished this list with better news, but unfortunately the only way to ask a process to terminate is, yes, signals.
The DOs:
Use a lockfile to ensure a single instance of your controller is running.
Use process groups.
Handle SIGCHLD if your OS uses it to signal child processes exiting.
Use systemd if your OS has it. It might get kind of long to config properly (especially for a dynamic list of processes), though.













 and
and  are the two sets, and
are the two sets, and 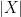 and
and 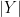 are their size.
are their size. 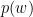 is the probability of item
is the probability of item  (simply put, the frequency of word
(simply put, the frequency of word 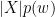 is the probability of
is the probability of 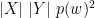 is the probability an item
is the probability an item
You must be logged in to post a comment.